

After a rough twelve months, Meta came back on April 9, 2026, with Muse Spark, its most powerful AI model to date. This is the first model from Meta Superintelligence Labs, the AI unit the company assembled under Alexandr Wang after spending $14.3 billion to bring him over from Scale AI. Meta is calling Muse Spark the first step toward personal superintelligence, an AI assistant that understands your world because it is built around it.
This launch marks a shift in Meta strategy, Muse Spark is not open-source. Meta says it "hopes to open-source future versions" but has not committed to any date. Unlike the open-weight Llama models that anyone could download and modify freely, Muse Spark is closed and proprietary. The model is free at meta.ai and in the Meta AI app, with rollout coming to WhatsApp, Instagram, Facebook, Messenger, and Meta's Ray-Ban AI glasses over the next few weeks.
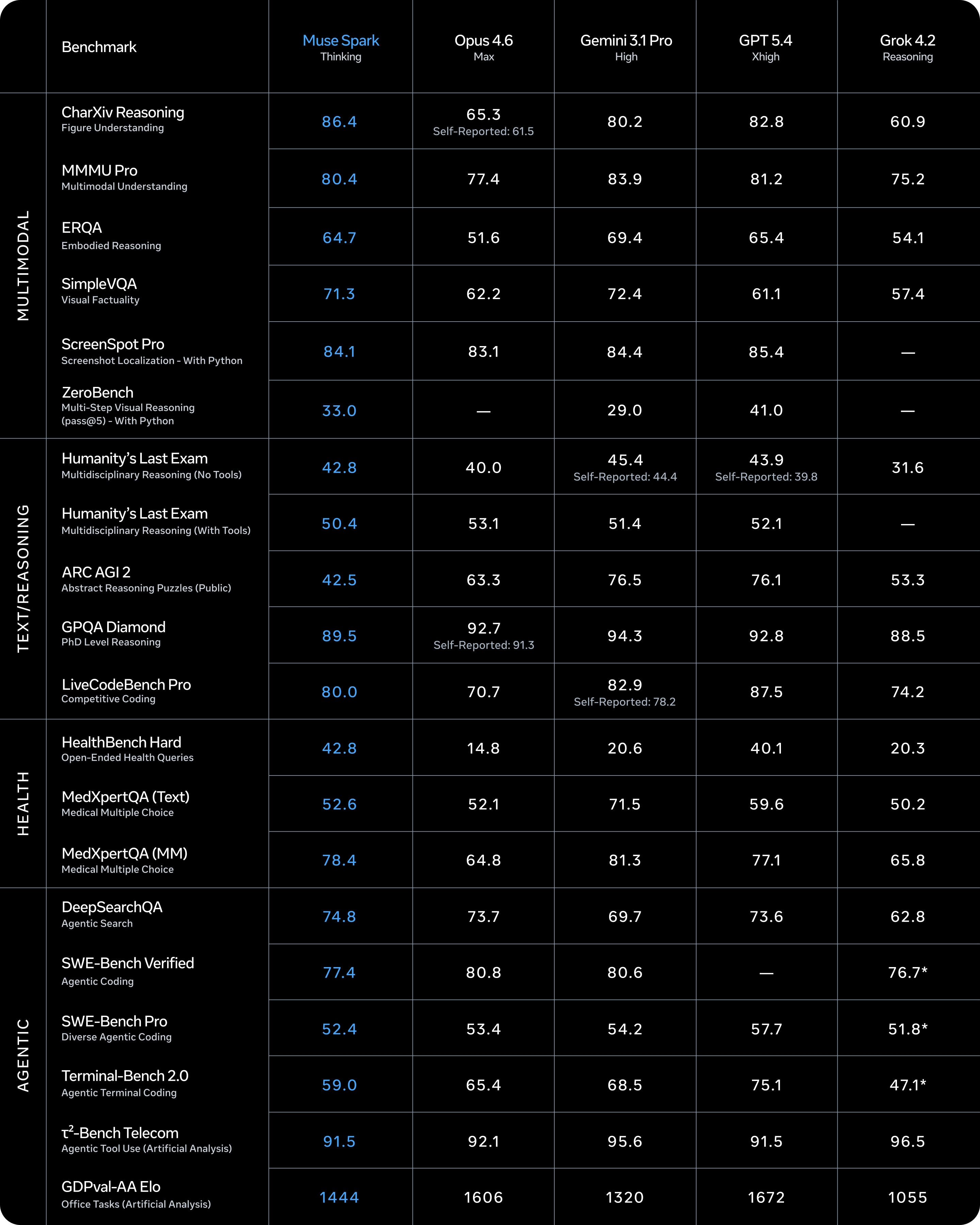
So, how good is Muse Spark? It scores 52 on the Artificial Analysis Intelligence Index, placing it fifth globally behind GPT-5.4 and Gemini 3.1 Pro at 57 and Claude Opus 4.6 at 53. On health reasoning benchmarks it leads every competitor by a wide distance, and its Contemplating mode outperforms both Gemini Deep Think and GPT-5.4 Pro on Humanity’s Last Exam.
This model is competitive but not dominant. In several areas that matter most to developers and power users, Muse Spark still trails GPT-5.4, Gemini 3.1 Pro and Claude Opus 4.6 by meaningful margins according to the benchmarks. Here are five of them.

1. The model can’t solve abstract reasoning puzzles anywhere close to ChatGPT or Claude
The biggest gap in the entire benchmark table is on ARC-AGI-2, which tests abstract reasoning, the ability to identify visual patterns and solve problems the model has never encountered in training. Muse Spark scores 42.5. GPT-5.4 scores 76.1. Gemini 3.1 Pro scores 76.5. That is not a minor shortfall, it is less than half their score on a benchmark specifically designed to resist memorisation. For anyone using AI in creative problem-solving, novel analysis, or tasks that require genuine generalisation rather than pattern recall, this is the most important number in the release.
2. Muse Spark doesn’t handle everyday computer tasks as well as ChatGPT or Claude
On GDPval-AA Elo, which measures how well a model autonomously handles actual desktop and office workflows, think filling spreadsheets, navigating websites, managing documents. Muse Spark scores 1,444. Claude Opus 4.6 scores 1,606. GPT-5.4 scores 1,672. This is the benchmark that most closely reflects how AI performs when someone hands it a real task and walks away. A gap of over 200 ELO points here is the difference between a model you can trust to finish a job and one you still need to babysit.
3. It falls short on competitive and agentic coding
Coding is where the gaps compound. On Terminal-Bench 2.0, which tests agentic terminal coding, Muse Spark scores 59.0 against GPT-5.4’s 75.1 and Gemini 3.1 Pro’s 68.5. On LiveCodeBench Pro for competitive coding, it scores 80.0 against GPT-5.4’s 87.5. On SWE-Bench Pro, which tests diverse agentic coding across real software engineering tasks, it posts 52.4 against GPT-5.4’s 57.7. None of these gaps are very poor seperately, but taken together points that Muse Spark is weaker across the full range of coding benchmarks, which is a significant limitation for the developer community Meta needs to win over.
4. Muse Spark doesn’t match rivals on certain medical knowledge tests
Health AI is Meta’s loudest claim with this launch, they worked with over 1,000 physicians to curate training data, and on HealthBench Hard, Muse Spark genuinely dominates with a score of 42.8 against Gemini’s 20.6 and GPT-5.4’s 40.1. But a different medical benchmark highlighted a challenge. On MedXpertQA Text, which tests medical multiple choice knowledge, Muse Spark scores 52.6 against Gemini 3.1 Pro’s 71.5 and GPT-5.4’s 59.6. Health is the one category Meta explicitly positioned as a strength, so the gap here, on a benchmark covering textbook medical knowledge rather than open-ended health reasoning, is worth noting.
5. The model can’t keep up with Rivals on PhD-level scientific reasoning
On GPQA Diamond, which tests PhD-level reasoning across physics, biology, and chemistry, Muse Spark scores 89.5. That number sounds strong but Gemini 3.1 Pro scores 94.3, GPT-5.4 scores 92.8, and even Claude Opus 4.6 self-reported 91.3. The gap is slight here compared to the other categories, but for researchers, scientists, and technical users who need a model that can hold its own in advanced scientific domains, Muse Spark is still coming in last among the frontier models on the benchmark that matters most.
What Is Meta Doing About These Gaps
Meta did not bury any of this. The technical blog post that announced Muse Spark openly stated that the company “continues to invest in areas with current performance gaps, such as long-horizon agentic systems and coding workflows.” Meta named its own weaknesses before anyone else had the chance to, which at minimum suggests the team went into this release clear-eyed about where the model currently stands.
Wang and his team have positioned Muse Spark as step one of a scaling plan toward personal superintelligence, with larger models already in development. Meta says its rebuilt stack can reach the same performance level as Llama 4 Maverick using more than ten times less compute, which the company argues makes future improvements faster to ship. The next model in the Muse series will be the real test of that claim.





