

The Google I/O 2025 event just kicked off, and they unveiled a long list of things. But the common denominator? AI, with Google Gemini being slapped on pretty much everything at the event.
The 2025 event built heavily on last year’s announcements, introducing a suite of enhancements to Gemini’s capabilities, including new models, features, and subscription plans. We called some of them a couple of days ago, but of course, there were several updates we didn't see coming.
From voice interactions and personalised context to high-resolution media generation, here’s a breakdown of the major Gemini updates unveiled at Google I/O 2025.

Gemini 2.5 Pro and Flash: Power Meets Performance
Leading the announcement lineup was Gemini 2.5, Google’s most advanced AI model to date. According to the company, Gemini 2.5 Pro delivers improved performance across reasoning, planning, and long-context understanding. It supports context windows of up to 1 million tokens, enabling it to process large documents, audio transcripts, or codebases more effectively.
Gemini 2.5 Pro has been available in the Gemini Advanced subscription since March 2025, but Google used the I/O stage to highlight its performance benchmarks. The company claims it outperforms GPT-4 Turbo across multiple reasoning tasks, particularly in coding and logic-based evaluations.
Introducing Gemini 2.5 Flash
Debuting at I/O 2025 is Gemini 2.5 Flash, a streamlined version of the Pro model, optimised for speed and efficiency. While it lacks some of the heavier reasoning capabilities of Pro, Flash is designed for high-volume, low-latency use cases like summarisation, quick image captioning, and data parsing.
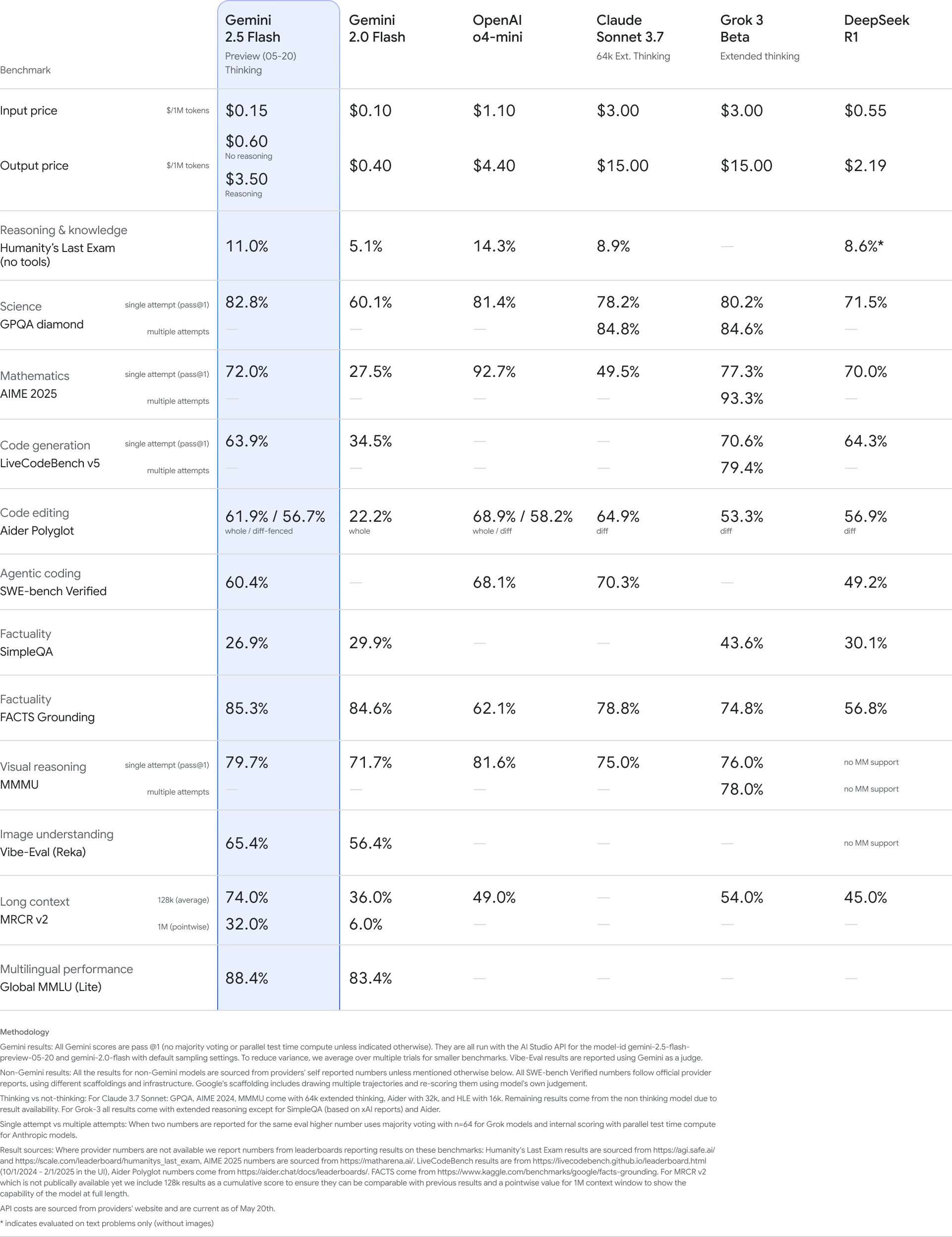
Flash also supports up to 1 million tokens and is available through Google’s Gemini API and Vertex AI, making it ideal for developers and enterprises needing responsive AI tools without the computational cost of deeper reasoning.
Deep Think: Encouraging Thoughtful AI Responses
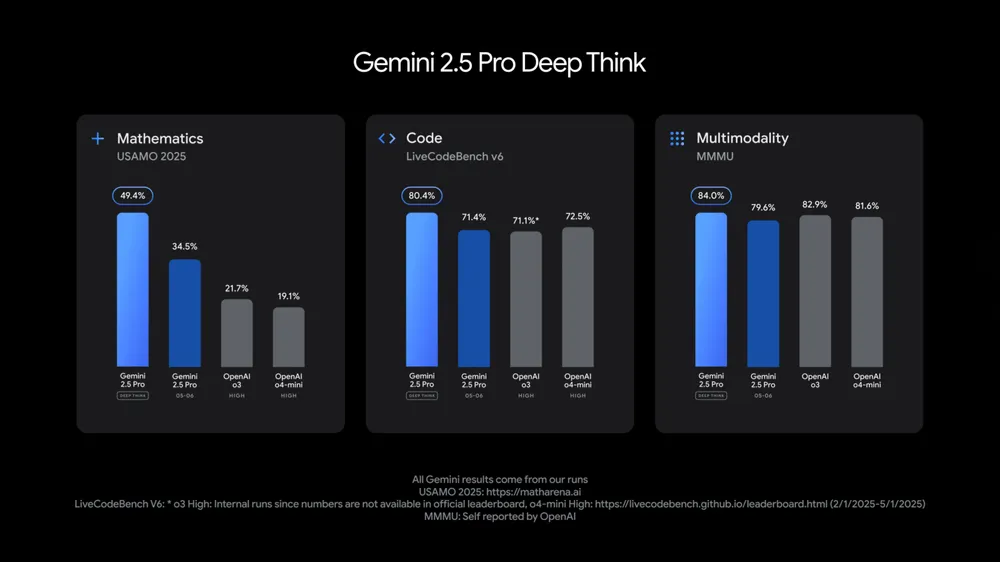
A new feature coming to Gemini 2.5 Pro is Deep Think, which allows users to instruct the model to take additional time when responding to complex queries. According to Google, this functionality helps improve the quality of results in cases that require deeper reasoning or longer-term planning.
For instance, tasks like analysing business strategies, drafting research summaries, or generating code for large projects may benefit from Deep Think’s more deliberate processing approach. The feature is expected to roll out gradually to Gemini Advanced users.
Gemini Gets Personal: Context-Aware Assistance
To make Gemini more useful in everyday tasks, Google introduced Personal Context, a feature that allows the assistant to draw on information from the user’s Google apps, like Gmail, Calendar, and Docs, to generate more personalised and relevant responses.
Video Credit: Google
With this update, Gemini can answer queries such as “What time is my next flight?” or “Summarise my recent meetings,” by referencing content from your inbox or schedule. Google emphasised that this integration will be opt-in, and users will have control over what data is accessed, along with options to pause or delete context history.
Imagen 4: Enhanced Text-to-Image Generation
In the area of creative AI, Google announced Imagen 4, the latest version of its text-to-image generation model. Now available via ImageFX and the Gemini API, Imagen 4 offers higher fidelity and more detailed image outputs than previous versions.

According to Google, the model has been optimised for photorealism, object coherence (like accurate hand generation), and improved lighting. These upgrades are designed to support content creators, advertisers, and developers seeking high-quality visuals from simple text prompts.
Veo: AI-Generated Video at 1080p
Google’s latest upgrade to its video generation model, Veo 3, now adds audio alongside its 1080p visuals. The model can generate not just video from text prompts but also soundtracks and ambient audio that match the scene.
In one demo called Old Sailor, Veo created a cinematic clip of an elderly man at sea—complete with voiceover narration and realistic ocean sounds. According to Google, both the visuals and the audio were AI-generated, showing how the model can handle storytelling with greater depth and immersion.
Credit: Google
While the audio feature is still early, it marks a shift toward more complete, multimodal content creation. Veo is available in limited preview through VideoFX, with wider access expected soon.
Flow: Bringing Imagen and Veo Together
Google’s new Flow interface ties the creative capabilities of Imagen 4 and Veo 3 together, giving users a unified workspace for multimodal content creation.
Flow allows users to combine text, image, and video generation into a seamless workflow. For instance, a user could start by describing a scene in text, use Imagen to generate the imagery, and then pass that output into Veo to generate a corresponding video.
Video Credit: Google
The tool is intended to simplify the process for creators, offering intuitive control over visual storytelling using AI. While still in early access, Flow reflects Google’s broader ambition to make Gemini a central tool for all kinds of creative professionals.
Gemma3n: Efficient, Specialised AI Models
At Google I/O 2025, Google unveiled Gemma 3n, an open AI model engineered for efficient, offline operation on devices with less than 2GB of RAM. Gemma 3n supports multimodal inputs—including audio, text, images, and video—enabling developers to create responsive applications that prioritise user privacy by processing data locally .
Additionally, Google introduced MedGemma, a model tailored for analysing medical text and images, and SignGemma, designed to translate American Sign Language into spoken-language text. Both models are available through Google's Health AI Developer Foundations program, offering developers specialised tools for healthcare and accessibility applications.
New AI Plans: Google AI Pro and Google AI Ultra
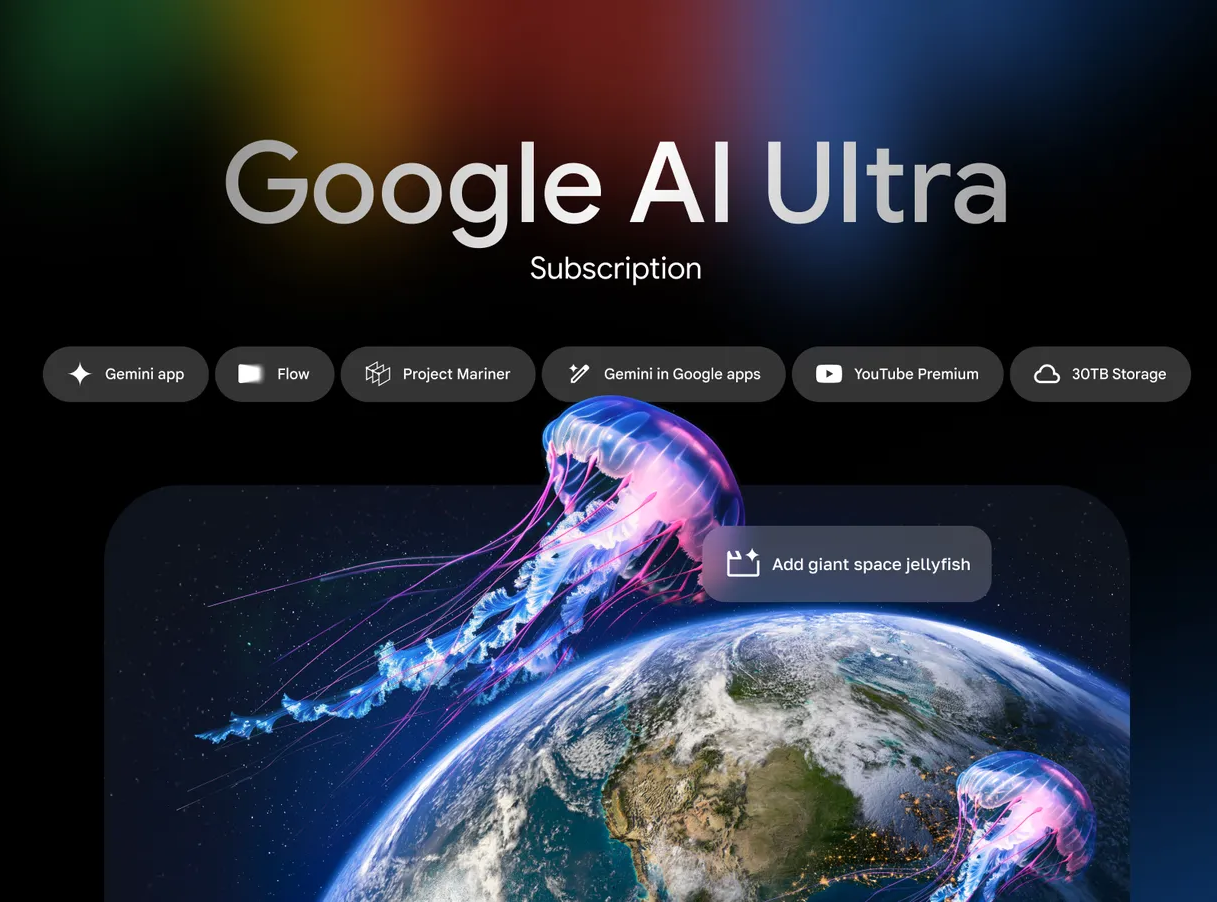
To support these capabilities, Google introduced updated subscription tiers under the Google One AI Premium banner:
- Google AI Pro ($19.99/month): This plan offers access to Gemini 2.5 Pro, the Deep Think feature, and 2TB of cloud storage. It’s targeted at professionals and power users who need reliable AI support across tasks.
- Google AI Ultra ($249.99/month): A premium offering designed for enterprise users, Ultra includes access to the most advanced AI tools, like Veo 3 and Imagen 4, along with 30TB of storage and additional benefits such as YouTube Premium.

Conclusion
If you thought last year’s Google I/O had a bit too much AI, this year was a full-on flood. The focus on Gemini was expected, especially with Android now getting its own separate spotlight, even though AI still managed to seep into that as well.
Many of these new features feel like early glimpses of what could be transformative down the line. But as with any major shift, especially in creative fields, pushback is inevitable. The real test will be how Google navigates the balance between innovation and responsibility in the months ahead.





