

Graph algorithms are at the heart of modern computing, powering social networks, bioinformatics, logistics, and artificial intelligence. But as graphs become complex, traditional CPU-based processing struggles to keep up.
For years, graph algorithms have faced slow execution speeds, memory limitations, and inefficient data transfers.
And that’s when GPUs arrived.
With their ability to process thousands of threads simultaneously, GPUs transform graph traversals, query execution, and real-time analytics.
However, leveraging GPUs effectively is not as simple as porting code. It requires optimized graph segmentation, efficient memory management, and minimal I/O overhead.
This realization led to the question: How do we make GPU-accelerated graph processing as fast and efficient as possible?
The Challenges of Running Graph Algorithms on GPUs
GPUs have demonstrated their power in accelerating deep learning, image processing, and numerical simulations. However, graph algorithms pose unique challenges:
- Irregular Memory Access: Unlike dense matrix computations, graph algorithms involve irregular memory accesses, making it harder to utilize the GPU’s parallelism fully.
- Graph Partitioning & Segmentation: To fit large graphs into GPU memory, they must be segmented efficiently while maintaining connectivity for traversals.
- Efficient Data Loading: Selecting and loading the right segments into GPU memory for specific queries is crucial to minimize I/O overhead.
- Minimizing GPU I/O Overhead: Transferring graph data between the CPU and GPU incurs significant latency, affecting query execution time.
- Query-Specific Optimizations: Different queries may require different partitioning strategies for optimal performance.
Effectively addressing these challenges is essential to unlocking the full potential of GPUs for efficient and scalable graph algorithm execution.
Segmenting Graphs for GPU Processing
Effective segmentation is crucial to overcoming the challenges of processing large graphs on GPUs. By breaking graphs into manageable subgraphs, we can optimize memory usage, improve traversal efficiency, and reduce the performance impact of memory transfers.
1. Partitioning Graphs for Efficient GPU Computation
Graph partitioning is key to efficiently using GPU memory. The goal is to segment graphs into subgraphs that:
- Fit into GPU memory.
- Maintain connectivity for traversal algorithms.
- Minimize inter-segment dependencies to reduce memory transfers.
Graph Partitioning Strategies
Several strategies exist for graph segmentation:
- Vertex-Centric Partitioning: The graph is divided based on nodes, assigning connected subgraphs to different partitions.
- Edge-Centric Partitioning: The focus is on partitioning edges, ensuring balanced workloads per GPU thread.
- Hybrid Partitioning: Combines vertex and edge partitioning to minimize cross-partition communication.
A well-partitioned graph reduces the GPU I/Os needed to answer queries and maximizes GPU utilization.
2. Selecting Graph Segments for Query Execution
When a user submits a query, determining which segment of the graph should be loaded into the GPU is crucial. The decision depends on:
- Query Scope: Only relevant segments must be loaded if a query targets a localized graph area.
- Traversal Depth: To maintain connectivity, deeper traversals require larger subgraphs to be loaded.
- Data Dependencies: Queries that require connections across multiple segments may need efficient cross-segment data retrieval.
Dynamic loading strategies, such as on-demand streaming of graph segments, allow GPUs to load only the necessary data, reducing memory overhead.
Running Graph Traversal Queries on GPUs
Graph traversal algorithms such as Breadth-First Search (BFS) and Depth-First Search (DFS) are fundamental for answering user queries. GPUs can significantly speed up these algorithms by leveraging thousands of cores for parallel processing.
Parallel Execution of Graph Traversal
Traditional graph traversal algorithms rely on queue-based or stack-based implementations, which introduce sequential dependencies. To optimize traversal on GPUs:
- Frontier Expansion: Parallelization is achieved by concurrently expanding the frontier of visited nodes.
- Warp-Level Execution: CUDA threads are grouped into warps that process multiple nodes simultaneously.
- Minimizing Memory Divergence: Data structures are optimized to ensure coalesced memory accesses.
These optimizations enable GPUs to excel in graph traversal, making them essential for large-scale, complex data processing.
GPU I/O Optimization for Graph Queries
One of the main performance bottlenecks in GPU-accelerated graph algorithms is the cost of I/O operations. Every time a graph segment is loaded from CPU to GPU memory, it incurs a latency penalty.
Reducing GPU I/O Overhead
Several techniques help minimize GPU I/O:
- Batch Loading: Instead of loading one node at a time, batching multiple queries reduces redundant memory transfers.
- Compression Techniques: Graph data can be compressed before transfer, reducing memory bandwidth requirements.
- Persistent Data Structures: Frequently accessed graph segments can be cached in GPU memory to avoid repeated loading.
Implementing these techniques ensures GPUs can process graph queries more efficiently by reducing data transfer latency and optimizing memory usage.
Trade-offs Between GPU and CPU Execution
Running graph algorithms on GPUs achieves significant speedup, but not all queries benefit equally. Some graph workloads still perform better on CPUs due to:
- Low-Degree Nodes: If most nodes have few edges, the overhead of launching GPU kernels may outweigh the benefits of parallelism.
- Small Graphs: The benefits of GPU acceleration are more pronounced for large graphs with high connectivity.
Balancing optimizations with graph and query characteristics allows GPUs to maximize performance while minimizing I/O bottlenecks.
Performance Comparison: GPU vs. CPU for Graph Queries
Understanding the performance differences between GPUs and CPUs is essential for evaluating the effectiveness of GPU acceleration in graph processing.
Speedup of Queries Using GPUs
To illustrate the performance gains, we compare the execution times of common graph queries on GPUs and CPUs.
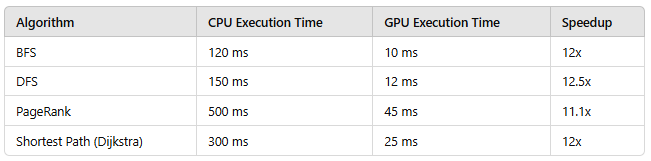
The results indicate that GPUs achieve a 10x–12x speedup over CPUs for various graph algorithms.
Factors Affecting GPU Speedup
Several factors influence the speedup observed:
- Graph Density: Dense graphs benefit more from GPU parallelism.
- Traversal Breadth: Wide traversals perform better due to high thread occupancy.
- Memory Bandwidth Utilization: Efficient memory access patterns significantly improve performance.
These results showcase GPUs' power in processing complex, dense graphs with high parallelism and efficient memory use.
CUDA Implementation of Graph Algorithms
CUDA has revolutionized the way complex graph algorithms are executed by offering a powerful platform for parallel processing.
Optimizing Graph Processing with CUDA
CUDA (Compute Unified Device Architecture) is the dominant framework for running graph algorithms on NVIDIA GPUs.
Key optimizations include:
- Thread Mapping: Assigning nodes to CUDA threads efficiently.
- Shared Memory Utilization: Reducing global memory accesses using shared memory.
- Warp-Level Synchronization: Ensuring efficient parallel traversal.
Example: CUDA Implementation of BFS
A simple BFS implementation in CUDA follows these steps:
- Load the graph into GPU memory.
- Assign each frontier node to a CUDA thread.
- Expand the frontier in parallel.
- Store results and update the queue for the next iteration.

This kernel executes BFS traversal in parallel by expanding the frontier nodes.
These CUDA optimizations unlock the full potential of GPUs, allowing them to handle graph traversal tasks with remarkable efficiency and speed.
Advancements in GPU-Based Spatial Data Queries
Previous research identified Spatial Distance Histograms (SDH) as crucial for scientific simulations, but brute-force methods proved inefficient for large datasets. GPU-accelerated approximate algorithms using Quad-tree structures drastically reduced computation time while maintaining accuracy.
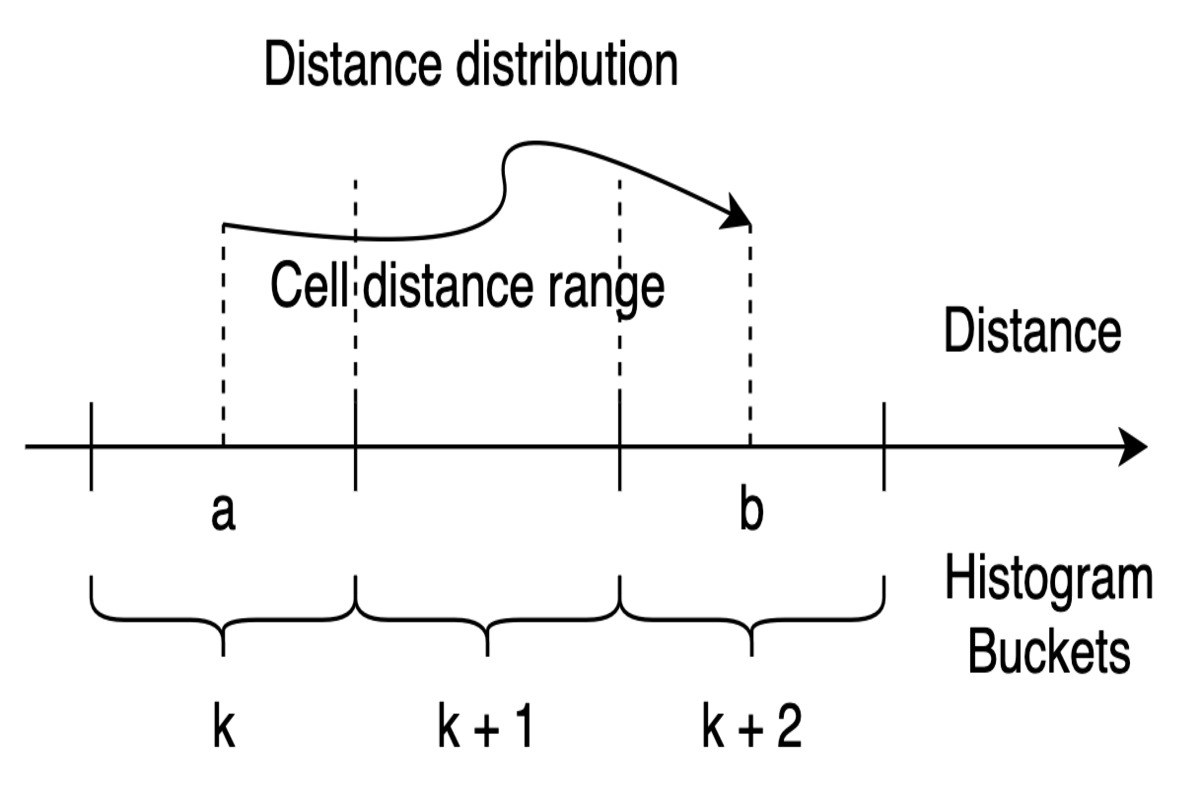
The key idea is to derive the statistical distribution of distances between particles, using Quad-tree nodes to capture both spatial and temporal locality across consecutive periods.
The illustration below explains the process of SDH computation using bucket-based distance ranges to calculate inter-cell distributions:
Impact and Adoption
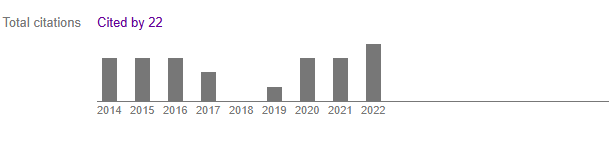
The chart below highlights the number of citations for this research, peaking in 2022 when interest in optimizing SDH computation on GPUs reached a high point. This trajectory underscores the growing recognition of GPU-based solutions in handling large-scale scientific simulations.
Relevance to Graph Algorithms
The concepts of graph algorithms are applied to SDH computation on GPUs. Similar principles, such as partitioning data into localized structures (e.g., Quad-trees for spatial data or segments for graphs), reduce memory access overhead and enhance GPU utilization.
These advancements in GPU acceleration boost efficiency, enabling scalable and high-performance graph processing.
Future Directions in GPU-Based Graph Algorithms
As graph datasets expand, future advancements in GPU-based algorithms will focus on improving efficiency, scalability, and adaptability to dynamic workloads.
1. Real-Time Graph Processing
With the growing demand for real-time analytics, optimizing GPU-based graph algorithms will enable faster response times in applications such as fraud detection and recommendation systems.
2. Adaptive Graph Partitioning
Future research will focus on dynamic graph segmentation that adjusts partitions based on query characteristics, reducing memory overhead.
3. Multi-GPU Execution
Scaling graph algorithms across multiple GPUs will enable the processing of even larger graphs with minimal latency.
4. Machine Learning for Graph Optimization
AI-driven approaches can help predict query patterns and optimize data loading strategies dynamically.
These innovations will enhance GPU-driven graph processing, making it faster, smarter, and capable of handling complex data.
The rise of GPU-accelerated graph algorithms has significantly improved computational efficiency, transforming how experts analyze large and complex graphs.
Advancements in segmentation strategies, memory management, and parallel processing enable GPUs to set new benchmarks for speed and performance, driving innovation across bioinformatics, artificial intelligence, and beyond.
About the Author
Anand Kumar is a high-performance computing researcher specializing in GPU-accelerated graph algorithms. With expertise in CUDA programming and partitioning, he advances graph processing and spatial analysis—his work bridges theory and application, driving computational innovation.
References
1. ScienceDirect. (2019). Accelerating genetic algorithms with GPU computing: A selective overview. https://www.sciencedirect.com/science/article/abs/pii/S036083521830665X
2. IEEEXplore. (2016). Optimizing Graph Processing on GPUs. https://ieeexplore.ieee.org/abstract/document/7572196
3. ACM Digital Library. (2012). Efficient SDH computation in molecular simulations data. https://dl.acm.org/doi/abs/10.1145/2382936.2383010
4. SageJournal. (2013). BenchFriend: Correlating the performance of GPU benchmarks. https://journals.sagepub.com/doi/abs/10.1177/1094342013507960
5. Springer Nature Link. (2007). Accelerating Large Graph Algorithms on the GPU Using CUDA. https://link.springer.com/chapter/10.1007/978-3-540-77220-0_21




