

Cloud dependency has been the price of using frontier AI coding tools. You either paid for API access or accepted that the most capable models lived on someone else’s servers. Zhipu AI’s GLM-4.7-Flash, released January 19, is challenging that assumption with a lightweight model designed to run entirely on consumer hardware.
Built on a 30-billion parameter Mixture-of-Experts architecture with just 3 billion active parameters per token, the model runs efficiently on RTX 3090s and Apple Silicon machines. Early testing shows speeds reaching 82 tokens per second on an M4 Max MacBook Pro, according to EXO Labs, with other users reporting 43-81 tokens per second across various hardware configurations.
Zhipu AI positions GLM-4.7-Flash as “setting a new standard for the 30B class,” emphasizing its balance of performance with efficiency. The company offers free API access with one concurrent request, alongside GLM-4.7-FlashX, a faster paid variant. Beyond coding, the model is recommended for creative writing, translation, long-context tasks up to 200,000 tokens, and role-play scenarios.

The Benchmark Numbers
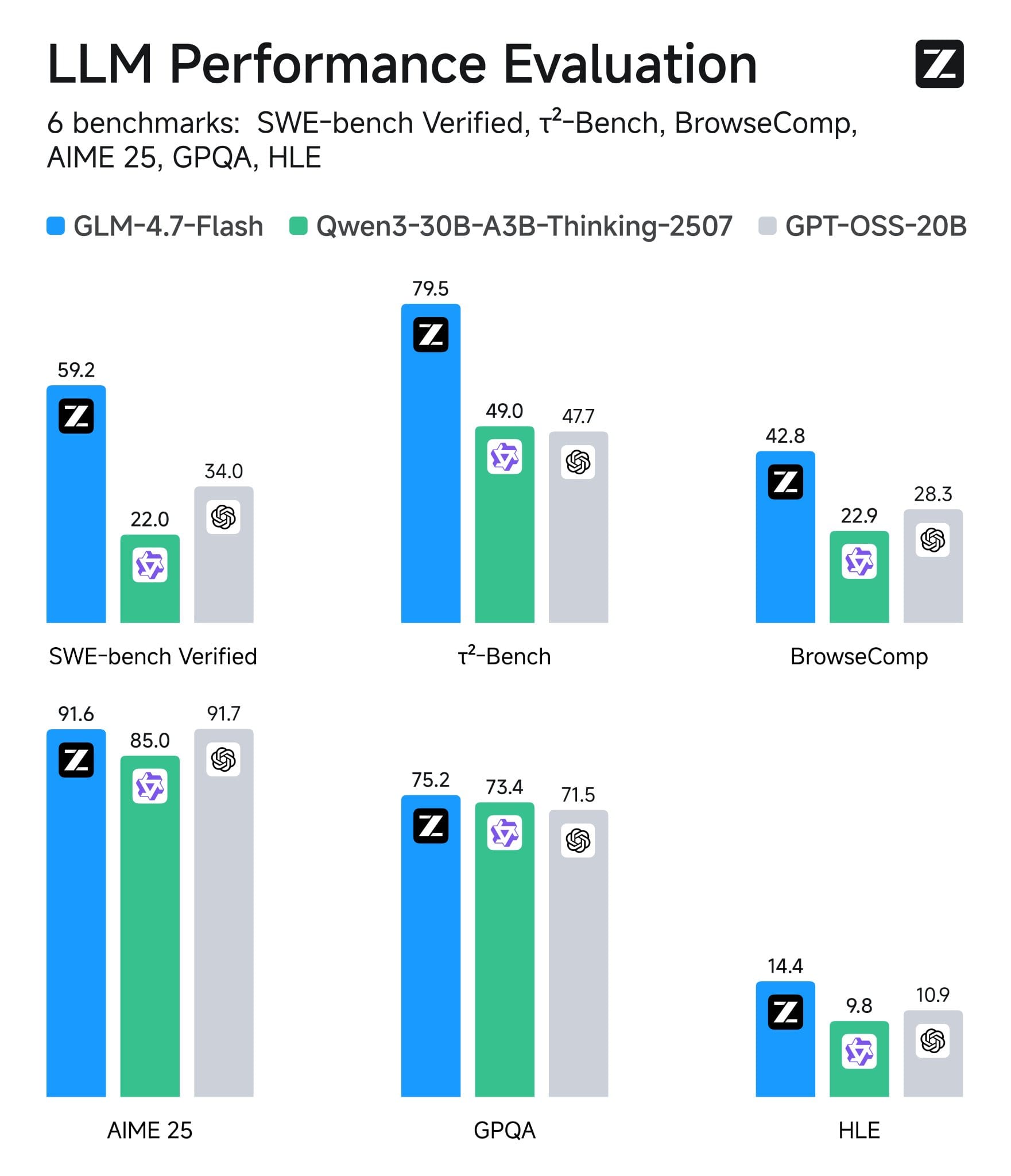
On SWE-bench Verified, which measures how well models fix real GitHub issues, GLM-4.7-Flash scored 59.2%. That’s notably ahead of Qwen3-Coder’s full 480B model at 55.4%, though still behind the full-size GLM-4.7 at 73.8% and DeepSeek-V3.2 at 73.1%.
One Hacker News commenter noted that while Anthropic’s Claude Codex delivers “notably higher quality,” it also makes users wait “forever.” The appeal of smaller models like GLM-4.7-Flash, they suggested, is getting models that “get better and better, not just at benchmarks” for practical daily work.
The model uses Multi-Headed Latent Attention (MLA) architecture, activating just 5 of its 64 total experts per token—fewer than competing models like Qwen3 which activate 9 of 128 experts. This design choice reduces computational overhead while maintaining competitive performance.
Local Deployment Takes Centre Stage
What’s driving early adoption is deployment flexibility. Zhipu AI released the weights open-source on Hugging Face with day-zero support in vLLM and upcoming integration in Ollama 0.14.3. Quantized versions are already available, with 4-bit and 8-bit variants running smoothly on consumer GPUs.
Infrastructure frameworks are moving quickly. vLLM announced day-zero support within hours of release, while LM Studio and other popular tools added the model shortly after. The speed of tooling support suggests strong developer interest in locally-deployable coding models.
For cloud users, pricing through z.ai and partners like Novita runs at $0.07 per million input tokens and $0.40 per million output tokens—substantially cheaper than premium alternatives from OpenAI, Anthropic, and Perplexity.
What Developers Are Seeing
Community response on Hacker News and X has been swift. Developers are integrating GLM-4.7-Flash into coding agents like OpenCode, Claude Code, Cline, and Roo Code. One developer using z.ai’s coding plan reported being “even more confident with the results” since GLM-4.7’s release, noting they use it alongside OpenCode rather than Claude Code.
Alex Cheema, an early tester, described it as “competitive with frontier coding models from ~a year ago” while running at over 80 tokens per second locally. “Great start to the year of local AI,” he noted on X.
Some caveats emerged. One Hacker News user testing through LM Studio on an M4 MacBook Pro reported it “feels dramatically worse than gpt-oss-20b,” with the model producing invalid code and getting stuck in loops. Others noted that while it works well for practical coding tasks, pure reasoning still lags behind specialized models.
The architecture’s newness also created initial friction. Llama.cpp support required updates, though a pull request was merged within 24 hours. These growing pains are typical for newly released architectures.
Whether local AI can match the convenience of cloud services long-term remains to be seen. But GLM-4.7-Flash demonstrates that the gap between cloud and consumer hardware deployment is narrowing faster than many expected—particularly for developers prioritizing control and cost over cutting-edge performance.





