

• A massive outage at Amazon Web Services (AWS) on October 20, 2025 knocked out hundreds of websites and apps globally.
• Over 11 million user-reports of issues in the U.S., U.K., Australia, and elsewhere.
• AWS said it was caused by a DNS (Domain Name System) issue, and although it was earlier reported "fully mitigated", several services continued to experience issues.
• The incident highlights how fragile modern digital infrastructure really is, as large parts of the internet are dependent on a small number of cloud-infrastructure providers.
A massive outage at Amazon Web Services (AWS) caused problems for several popular platforms and services on the internet, including Canva, Signal, Perplexity, Fortnite, Snapchat, Amazon, and Ring on Monday, October 20, 2025 about 9:30AM (GMT).
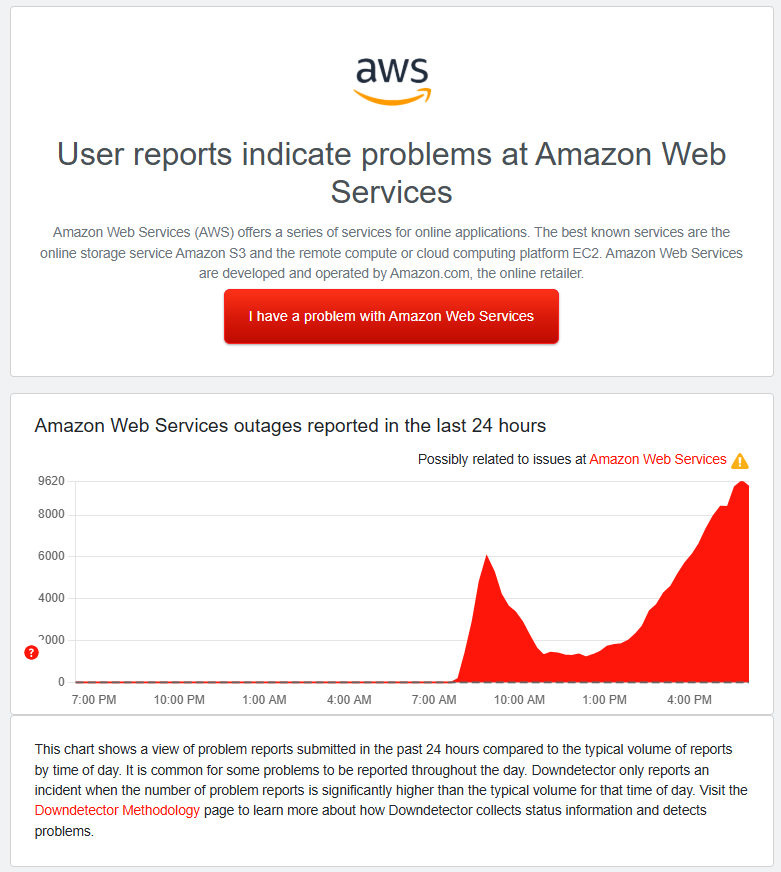
According to Downdetector, a website tracking service, hundreds of websites and apps were affected, and as of 14:45PM (GMT), more than 11 million reports were received from users in the United States (3M+), the United Kingdom (1M+), Australia, the Netherlands, Germany, Japan, and Europe who couldn’t access a website or app today.
“These figures highlight the global scale of the disruption,” Downdetector said on its website.
What caused the AWS outage?
The cause of the outage was unknown until after almost three hours. An update from AWS, Amazon's cloud service unit at 3:35 AM PDT (or 11.35AM GMT) reported that the underlying issue that caused today’s outage has now been “fully mitigated.
In the update, AWS says:
In case you don't know, DNS, or Domain Name System is used to map addresses on the Internet, by translating human-readable domain names such as www.techloy.com into numerical IP addresses that can be read by routers to direct traffic across the web.

Which websites and services were affected by the AWS outage?
Here are some of the notable websites and services that were affected due to the outage, according to Downdetector:
- Amazon
- AWS
- Amazon Alexa
- Prime Video
- Amazon Music
- Blink Security
- Roblox (Update: As at 3:45PM GMT, Roblox reports: “All Systems Operational”. Good news, kids!)
- Snapchat
- Robinhood
- Instacart
- Wordle
- Venmo
- Asana
- Apple Music
- Ring
- Grubhub
- Coursera
- Fortnite
- Epic Games Store (Update: The game store with games like Fortnite, Lego, and Rocket League is back online, as of 3:45PM GMT.
- Venmo
- Lyft
- Duolingo
- Jira Software
- Zoom
- Microsoft 365
- GoDaddy
- YouTube
- Max
- Tidal
- VRChat
- Chime
- Adobe Creative Cloud
- McDonald's app
- Hulu
- Signal
- Disney+
- Roku
- IMDb
- Capital One
- PlayStation Network
- Canva (Update: As of 11:27AM GMT, Canva says: "We have seen the majority of functionality recovered. Users may still see issues with downloading designs.")
- Coinbase
- Steam
- AT&T
- United Airlines
- T-Mobile
What has AWS said about the outage?
AWS has admitted that it is having problems, saying that "error rates and latencies have gone up" across a number of services. In a statement on its website, the company said that its engineers are "actively engaged" in both fixing the problem and figuring out what caused it.
An update from Amazon Web Services at 3:35 AM PDT (or 11.35AM GMT), reported that the underlying issue – DNS – which caused today’s outage has now been “fully mitigated.
While some services are being restored gradually, others still report problems. For example, Canva reports that “the majority of functionality” has been recovered, but also warns that "users may still see issues with downloading designs".
As of 1:30PM (GMT), it appears that the problem at AWS isn’t fully fixed yet. Two hours later at 3:15PM (GMT), Amazon Web Services reported it is still experiencing “elevated errors” when trying to launch new virtual servers on its cloud computing platform. At 4:50PM (GMT), AWS says it is now “throttling” requests for new virtual servers to speed up the recovery process.

Has this kind of outage happened before?
Last year, a simple update bug from CrowdStrike brought parts of the world to a halt. CrowdStrike’s cybersecurity software update impacted around 8.5 million devices in the US, UK, Australia, and worldwide. The company detected the problem and started addressing it in only 78 minutes, but the effects lasted for a long time.
For example, Delta Airlines had to cancel thousands of flights because of the disruption, and is currently suing the tech company. In the UK, things were especially bad as doctors couldn't get patient records and airport workers had to fill down boarding tickets by hand because important systems broke down.
The latest outage at AWS shows just how fragile modern digital infrastructure really is. As the tech world waits for the next promised update from AWS, this incident shows how much the internet depends on a small number of key providers. The current efforts to lessen the damage will determine whether this remains a short, manageable disruption or turns into a long, expensive crisis for thousands of businesses around the world.





